Hello my fellow tinkerers or should I say Hermes followers 😉 Today we'll set our sails into the deep trenches of computer caches, multi-core simulations, and persistent data structures. If you've ever thought about how modern systems juggle speed and data reliability, then you came at the right post. And don't worry—we'll start with the basics, much like learning to ride a bike (with training wheels, of course). And while none of us are Indiana Jones on a quest for hidden relics (or are we 🤨?), we're about to embark on our own little adventure, where we will bridge the gap between theoretical concepts and practical insights in a way that's as thrilling (hopefully) as it is enlightening.
#1 The Big Picture: What's a Cache?
Imagine you are in your kitchen preparing dinner. You wouldn't keep all your ingredients stored in a far-off storage or pantry (if you are fancy) every time you need a spice, right? So where would you keep it? Think 🤔—you know the answer.
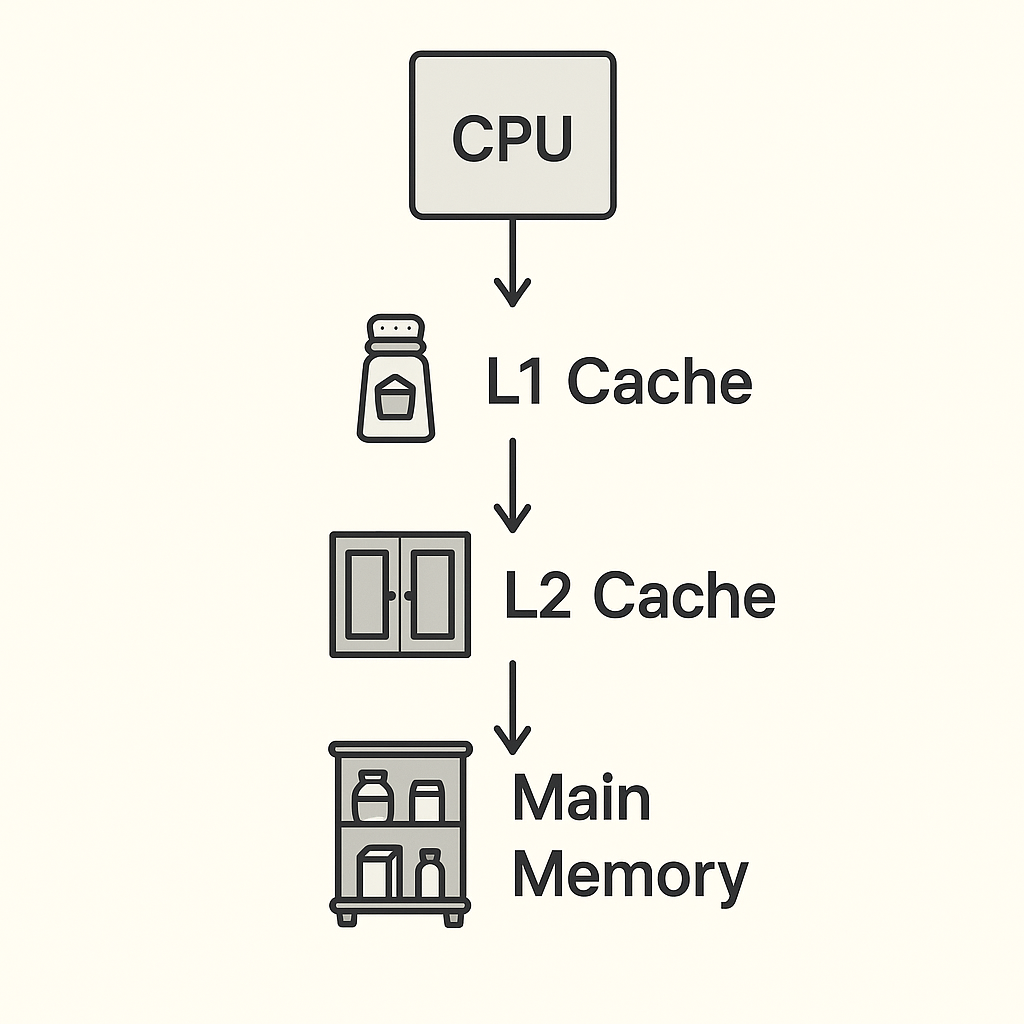
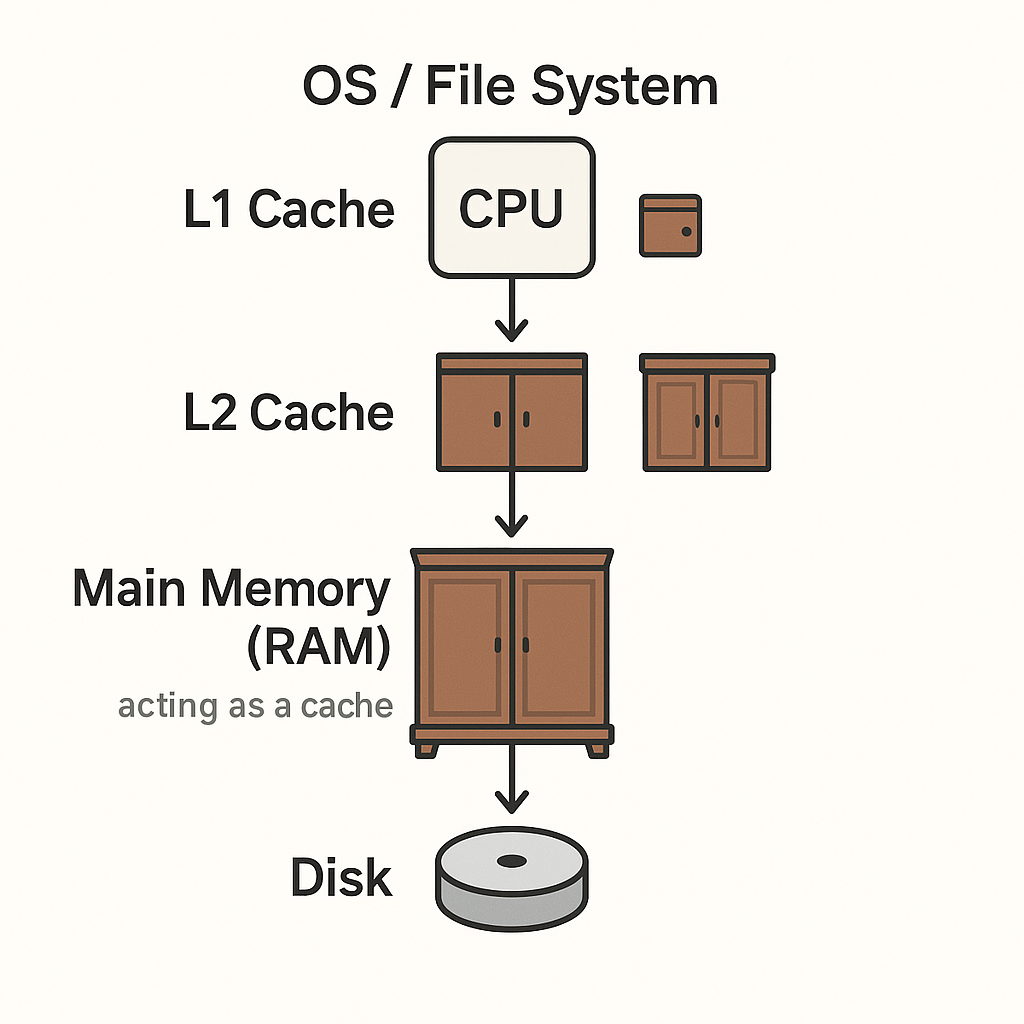
#2 Beyond the Basics: Splitting the L1 Cache
In many high performance processors, the L1 cache isn't a single, monolithic block. Instead, it's often split into two distinct parts:
- L1 Instruction Cache (L1i): Stores the instructions the CPU needs to execute, ensuring that the processor can quickly fetch and execute commands.
- L1 Data Cache (L1d): Holds the actual data that the processor operates on, keeping frequently used data readily accessible.
This split allows a CPU to simultaneously fetch instructions and access data, further optimizing performance. In our simulator, we focus on a unified L1 cache model to keep the concepts simple and clear. However, understanding the split nature of L1 in real-world processors can give you deeper insights into how modern systems maximize efficiency.
#3 Taking It Further: More Levels of Cache
While our simulator focuses on L1 and L2 caches for simplicity, real-world systems often include additional layers. For example:
- L3 Cache: Typically larger and shared among multiple cores, the L3 cache serves as a common pool of data that all cores can access. Yes, that makes it slower than L1 and L2 but still much faster than main memory. Think of it as a community pantry (if that's a thing) in a shared apartment everyone can use, though it's not as immediately accessible as your personal pantry.
- L4 Cache and Beyond: Some architectures even include an L4 cache or specialized caches, often used for specific purposes such as graphics processing or as a buffer between the CPU and slower system memory. These are even larger and act as the final fast-access stage before reaching the main memory.
#4 Simulating a Multi-Core World
Now, let's ramp things up a notch and really tighten our sails. Modern processors aren't just one kitchen; they're more like a bustling restaurant with several chefs (or cores) all working in parallel. Each core has its own L1 cache (its own countertop), yet they share a common L2 cache (a shared mini-fridge).
In our multi_core_simulation.cpp file, each core does its own thing:
- Writing Data: Every core writes data into its own L1 cache. Imagine each chef plating their dish.
- Flushing and Updating: Occasionally, a chef will "flush" data (or clean up the station—nobody likes a mess 😀) and update the shared L2 cache, ensuring the entire kitchen stays synchronized.
- Persistent Counter: One of the quirky bits is our persistent counter, a mechanism that not only increments but also "persists" the count to simulate durability—much like noting down orders on a notepad that won't get lost even if the kitchen goes chaotic.
This design lets us experiment with multi-threaded behavior and see how caches interact under concurrent operations.
#5 Bringing Persistence into the Mix
Persistence, in simpler terms, means endurance or the ability to hold on and continue. Just like Hercules conquered the 12 labours, let us conquer the system's volatility. Persistence isn't just for memories and photo albums—it's crucial for systems that need to remember their state even after a crash or reboot.
Our persistent_data_structure.cpp introduces a "PersistentCounter". In everyday terms, imagine a counter on your doorstep that not only counts the visitors but also writes down the total so it can be recovered later if the power goes out.
Here's how it works:
- Incrementing: Each time the counter increments, the new value is written into the cache.
- Persisting: A flush operation then simulates writing the value to a more permanent storage area.
If you go through the code you will see it uses a mutex to ensure that even if multiple "chefs" (or threads 😉) try to update the counter, everything stays in order.
#6 Real-Life Benchmarks and Simulations
Okay, so we discussed a lot about these chefs and what they can do, but it might be hearsay, right? Maybe it's just like when Dionysus boasted about an epic feast, yet all he served was an empty wine barrel! To truly understand performance—and avoid embarrassing ourselves like Dionysus—one must measure it.
Our project includes various benchmark modes (see benchmark.cpp and extended_benchmark.cpp) that simulate:
- Parallel Flushes: Several chefs simultaneously cleaning their stations.
- Redundant Flushes: Double-checking your recipes—ensuring you don't repeat work unnecessarily.
- Random Evictions: Occasionally, items get removed from the cache (or your countertop) unexpectedly—perhaps like a sudden gust of wind that knocks a spice container off the counter!
#7 Wrapping Up: Why It Matters
You might be wondering: why go through all this trouble to simulate caches and persistence? We're not Jack Sparrow—we're not setting sail for the world's end. Our aim is to show how modern software systems rely on these techniques to boost performance while ensuring data is never lost.
By experimenting with our simulator, you can:
- Visualize Complex Concepts: Break down the intricacies of caching, multi-threading, and persistence into manageable, bite-sized pieces.
- Optimize Real-World Systems: Gain insights into how to fine-tune systems for better performance—a crucial skill for developers and engineers.
- Have Fun with Code: And let's be honest, playing around with such simulations is just plain fun!
This concludes the first part of our exploration. In upcoming sections, we'll dive deeper into the code, explore each component in greater detail, and even run some of the simulations ourselves. Stay tuned for more playful insights into the fascinating world of caches and multi-core processing! Also here is the link for the Project: SkipCache
Happy coding, and may your caches always be hit! 😉
PS: I like Greek mythology and cooking, so most of the examples I include here or in later sections will be related to cooking or mythological characters. That doesn't mean I'm a good cook or an expert in ancient history. 😜
Leave a Comment